Transformer
Abstract
主流的序列转录模型(给一句英文生成一句中文)依赖于复杂的循环或卷积NN,使用Encoder和Decoder。性能最好的模型都会在Encoder和Decoder之间用注意力机制,本文仅使用简单的注意力机制架构,而不是循环或卷积NN。
最初用于NLP,后面用于图像等,都很有效。
Introduction
输入、输出中结构化信息较多时,使用编解码器架构会比较有效。
RNN中对第t个词计算一个$h_t$和$h_{t-1}$决定,因此时序过程难以并行(GPU上性能会比较差),且对于长序列无法存储过多$h_t$,早期的信息在后期会丢掉。
Attention这个思想已经在编解码器架构中使用。
新提出的Transformer不再使用RNN而是纯基于注意力机制。
Background
这里说了一些和Transformer结构类似或思想相关的模型。
CNN只能看到比较小的矩阵,无法看到整个序列的信息,但优点是有多输出通道,Transformer用Multi-Head Attention多头注意力机制模拟多通道。
模型结构图如下:
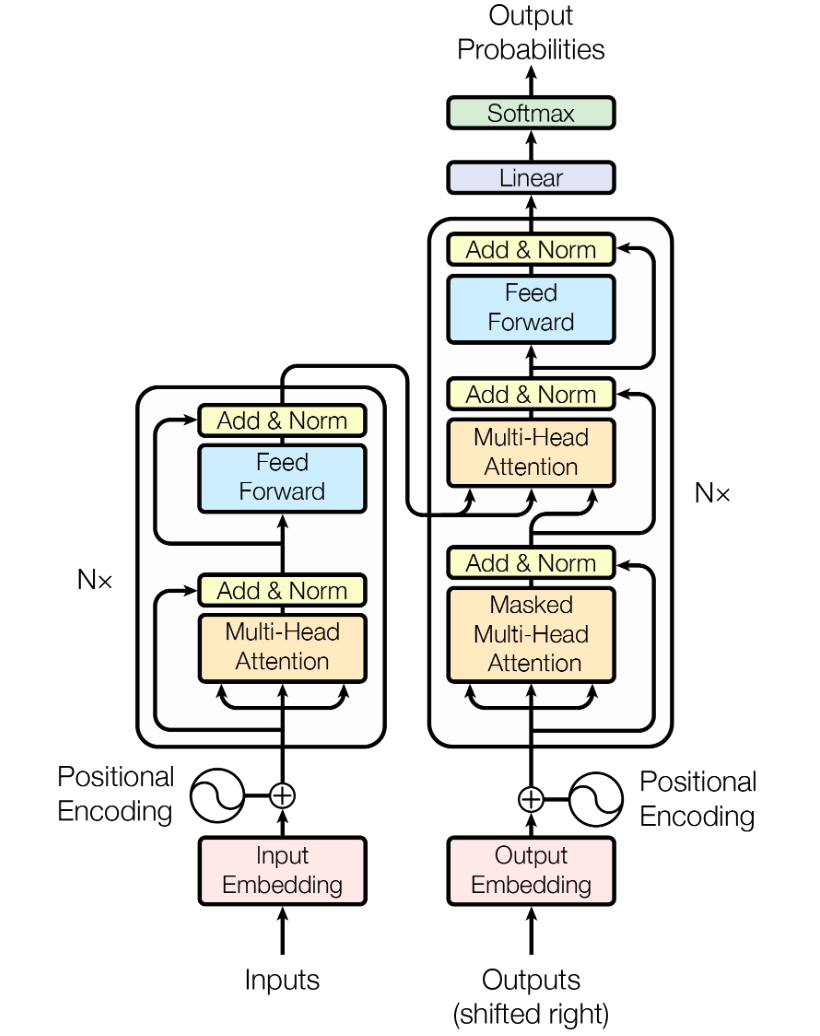
Model Architecture
编码器的输出是z向量,其中$Z_t$是第t个词的向量表示,编码器的输出作为解码器的输入,解码器的输出为$y_m$,即一个一个的生成,在得到y1后才能得到y2,因此是一个auto-regressive自回归模型,即输入就是输出。
把self-attention自注意力和point-wise堆叠起来重复N次。
输入:对单词进行embedding
编码器(图中左侧):用六个层堆叠起来的。每层里面有两个子层,第一个子层是多头注意力机制,第二个子层是MLP(图中的simple,position-wise fully connected feed-forward network),每个子层用一个残差连接,即LayerNorm(x+Sublayer(x))。每层输出维度都是512,方便进行残差连接,不同于CNN的设计。
解码器(图中右侧):自回归,当前的输入是上一个时刻的输出。解码器同样是用六个层堆叠。每层里面三个子层,第一个是带masked的多头注意力机制,是由于注意力机制每次可以看到所有的输入,用掩码防止在预测第t时刻的输出时看不到t时刻之后的输入。
输出:标准的神经网络输出,依次通过线性层和Softmax
Attention
注意力函数是将一个query和一些key-value对映射成输出的函数,这里的query、key、value、output都是向量。输出是value的加权和,每个value的权重是由value对应的key和query求相似度得到的。
Scaled Dot-Product Attention
缩放点积注意力机制最简单的一种Attention。
query和key的长度都是$d_k$,value长度为$d_v$。
- 权重的计算:对query和key做内积,内积值越大相似度越高,越小则说明两个向量正交,即没有相似度。将得到的内积除以$\sqrt{d_k}$(防止数据过大或过小导致softmax的结果分散到两端,最终导致梯度较小),然后通过Softmax得到n个权重。实际运算中,Q为query的矩阵,K为key的矩阵
$$
Attention(Q,K,V)=softmax(\frac{QK^T}{ \sqrt{d_k}})V
$$
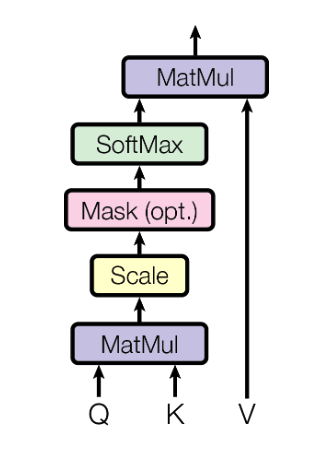
- mask:在计算第t时刻的输出时,不应该使用$K_t$以及之后的值,但在注意力机制中会计算出所有的K,所以需要将$K_t$以及之后的值换成非常大的负数(-1e10),这个负数在经过softmax的指数运算后会变成0。
多头注意力机制
先用线性层将query、key、value投影到低维度,然后做8次缩放点积注意力计算。这里多次投影、点积计算,类似于多输出通道。
$$
MultiHead(Q,K,V)=Concat(head_1,…,head_h)W^{Output}
$$
$$
head_i=Attention(QW_i^Q,KW_i^K,VW_i^V)
$$
TODO: 需要细读设计原因和投影
网络的输入输出(三个Attention的作用)
TODO:48min
前馈网络
结构:线性层 -> ReLU -> 线性层
两个线性层分别将512投影成2048,然后再将2048投影回512
Positional Encoding
在输入时就加入某一时刻的信息保证模型中带入时序信息。
缺点
Flowformer
虽然可以完成通用关系(image、language、time series、agent trajectory)的建模,但在self-attention的点积计算中,对数据是两两进行计算(比如image任务中每两两图片进行计算),如果是针对长序列计算代价过大。