【项目详情】DateMinder
概述:一款基于人工智能与云开发技术,为用户提供物品保质期记录提醒,与物品清单共享的小程序。
贡献:
- CLIP模型:使用Websocket动态更新清单。使用CLIP模型进行识别,并探究了Bert文本特征融合策略对检索的影响。
- 共享清单:使用 diff-match-patch 算法解决并发带来的多用户共同修改的冲突问题,使用高性能NoSQL,设计数据库权限划分,提高读写速度。
项目介绍
在生活中我们使用的大部分物品都有保质期,而我们往往难以做到清楚地记住每样物品的过期时间。导致在期限内未被使用而被浪费扔掉、或是由于使用过期产品对身心造成伤害,以及在家中,往往家庭成员无法记得其他成员购买的东西,导致重复购买同一类物品,而目前市面上的其他产品都不能很好的解决这些问题。
基于以上几种情况,我们开发的Date Minder——是一款基于人工智能与云开发技术,为用户提供物品保质期记录提醒,与物品清单共享的小程序。
我们希望通过数字化技术解决这一系列问题,为大家创造一个绿色、健康的生活环境,Date Minder 应运而生。
重点难点
共享清单
1、使用 diff-match-patch 算法解决并发带来的多用户共同修改的冲突问题。
2、使用高性能NoSQL,提高读写速度。
3、设计数据库权限划分。
4、使用Websocket动态更新清单。
物品识别模型 - CLIP
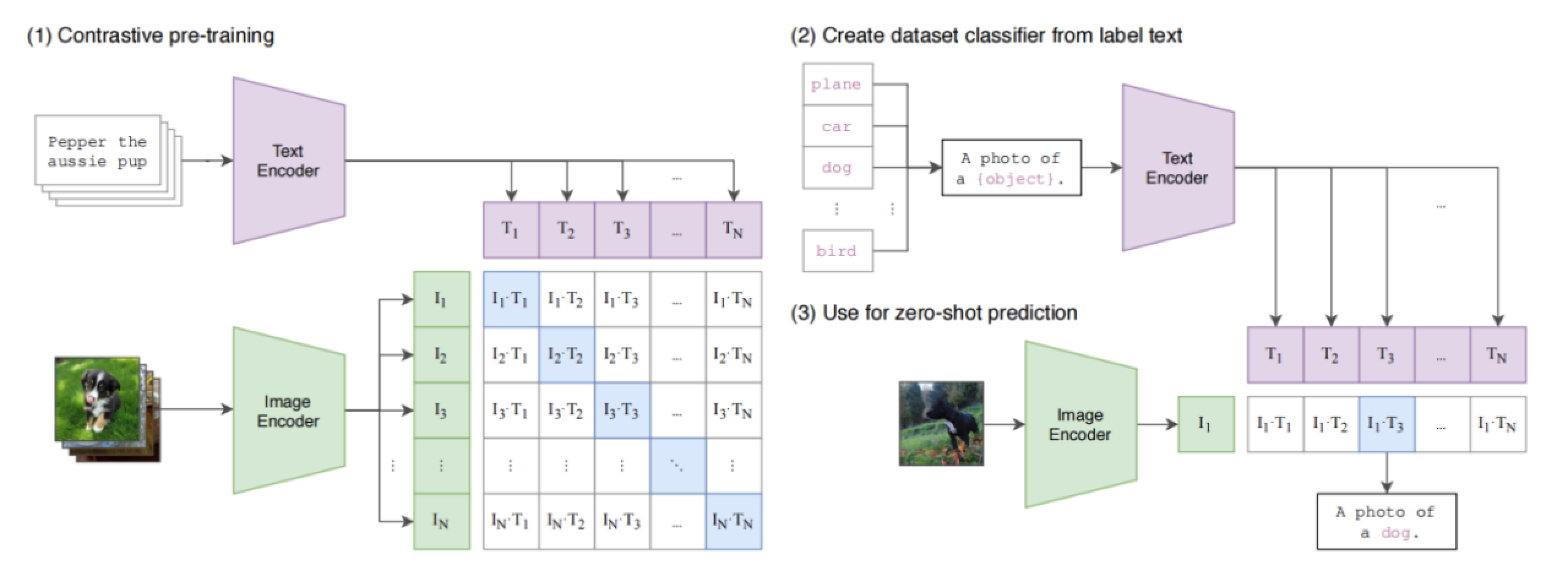
CLIP的模型采用的是经典的双塔结构,对于图片域和文本域有着不同的图片编码器(Image Encoder)和文本编码器(Text Encoder)。其中文本编码器采用了经典的Transformer结构,而图片编码器则采用了两种:第一种是改进后的ResNet,作者选择用基于注意力的池化层去替代ResNet的全局池化层,此处的注意力机制同样是与Transformer类似的多头QKV注意力;作者同样采用ViT结构作为第二种图片编码器进行实验。
CLIP的负样本采样,采用了in-batch负采样的方法。其CLIP模型也是经典的双塔结构。此时如图所示,对图片嵌入特征和文本嵌入特征进行矩阵相乘。那么形成的打分矩阵上,对角线上都是配对的正样本对打分,而矩阵的其他元素,则是由同个batch内的图片和不配对的文本(相反亦然)组成的负样本。而后只需要对每一行和每一列求交叉熵损失,并且加和起来即形成了总损失了。其中每一行可以视为是同个图片,与同个batch内其他所有样本对的文本进行组合构成的负样本对形成的损失,而每一列自然就是同个文本,对于每个图片进行组合而构成的损失了。
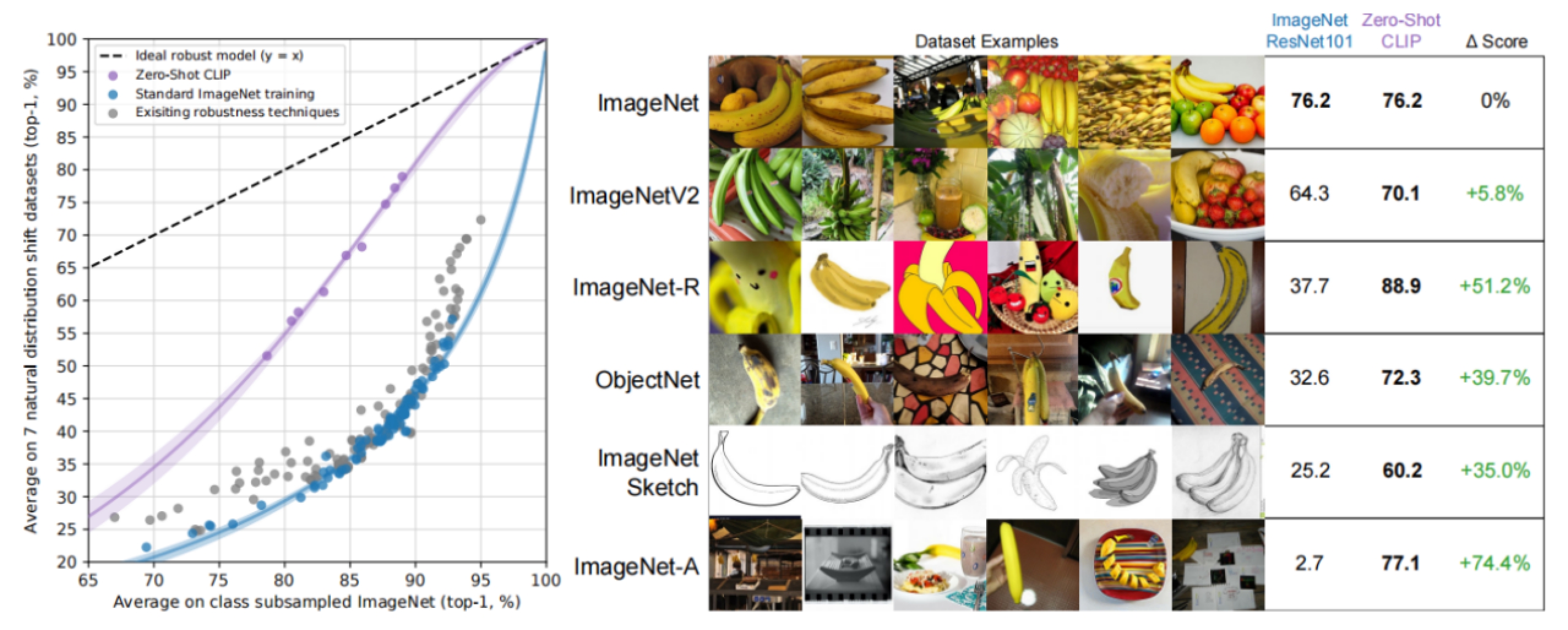
如下图显示,考虑到以单词作为标签存在多义的情况,比如在Oxford-IIIT Pet dataset 数据集中boxer表示斗牛犬,而在其他数据集中则可能表示拳击运动;在ImageNet中,crane同时表示了起重机和鹤。这种词语的多义显然对是因为缺少对标签的上下文描述导致的。为了解决这种问题,作者在指示上下文中添加了一些提示标签类型的词语,比如A photo of a
改进:Bert文本特征不同的融合机制
原始CLIP模型中只返回last hidden state和pooler_output,即cls最后一层的隐藏状态。CLIP一般使用最后一层的特征作为文本特征。
Bert输出是一个元组类型的数据,包含四部分: last hidden state shape是(batch_size, sequence_length, hidden_size),hidden_size=768,它是模型最后一层的隐藏状态。
pooler_output:shape是(batch_size, hidden_size),这是序列的第一个token (cls) 的最后一层的隐藏状态,它是由线性层和Tanh激活函数进一步处理的,这个输出不是对输入的语义内容的一个很好的总结,对于整个输入序列的隐藏状态序列的平均化或池化可以更好的表示一句话。hidden_states:这是输出的一个可选项,如果输出,需要指定config.output_hidden_states=True,它是一个元组,含有13个元素,第一个元素可以当做是embedding,其余12个元素是各层隐藏状态的输出,每个元素的形状是(batch_size, sequence_length, hidden_size)。attentions:这也是输出的一个可选项,如果输出,需要指定config.output_attentions=True,它也是一个元组,含有12个元素,包含每的层注意力权重,用于计算self-attention heads的加权平均值。
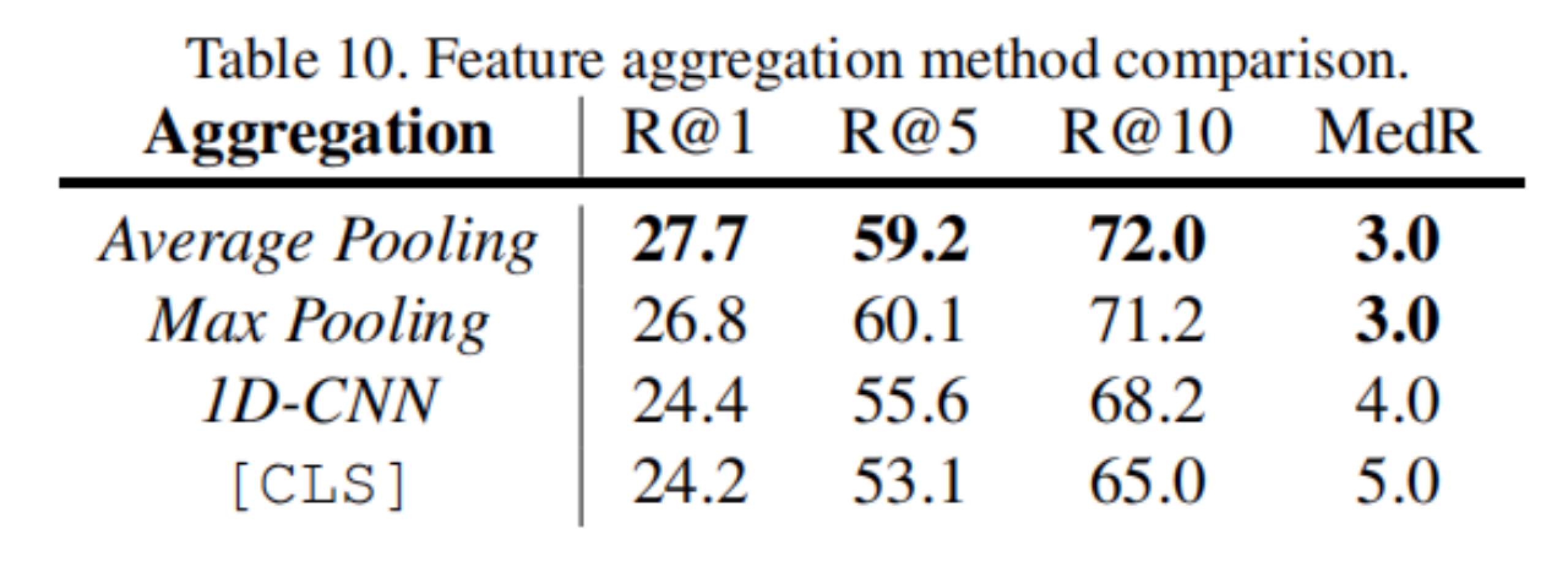
近期发表于ICCV2021关于跨模态视频检索的研究中,作者探究了Bert不同层特征聚合对检索的影响,如CLS,Maxpolling和Average Pooling,1D-CNN,发现使用Average Pooling的特征检索结果最好,受此启发,我们复现以上方法,对CLIP的文本特征使用所有层特征Average Pooling。
OCR识别模型 - StrucTexT
光学字符识别(OCR)是目前应用最为广泛的视觉AI技术之一。随着OCR技术在产业应用的快速发展,现实场景对OCR提出新的需求:从感知走向认知,OCR不但需要认识文字,也要进一步理解文字。因此,识别结构化文本逐渐成为OCR产业应用的核心技术之一,旨在快速且准确地分析卡证、票据、档案图像等富视觉数据中的结构化文字信息,并对关键数据进行提取。
StrucTexT是一个基于双粒度表示的多模态信息提取模型。除了采用字符粒度建模文本之外,StrucTexT利用字段组织文档视觉线索,并构建字符和字段的匹配关系对齐图像与文本特征。在多模态信息表示上,StrucTexT构建文本、图像和布局的多模态特征,并提出“遮罩式视觉语言模型”,“字段长度预测”和“字段方位预测”三种自监督预训练任务促进跨模态特征交互,帮助模型学习模态间的信息关联,增强对文档的综合理解能力。另外,StrucTexT支持中英双语编码。在双粒度表征下,模型能够实现字符和字段粒度的信息抽取任务,实现灵活选型和场景适配。
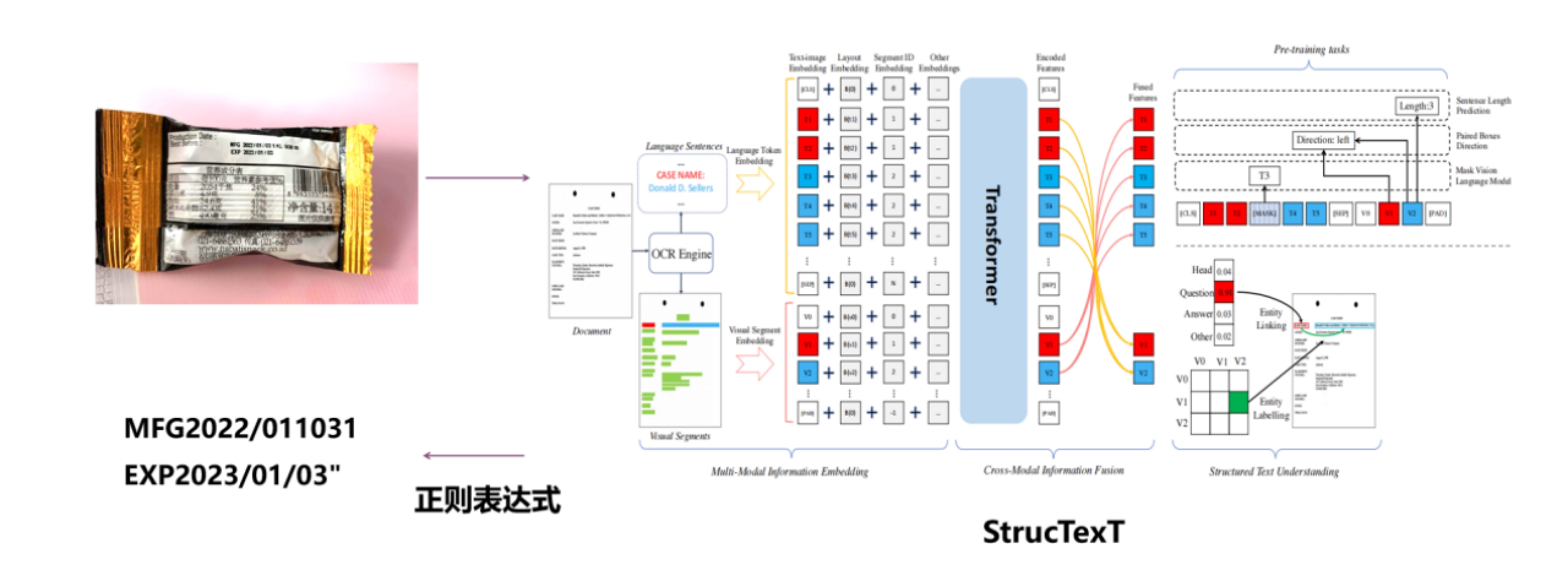
我们使用预训练模型StrucTexT作为程序识别文字的模型,同时,由于模型不能直接识别保质期,我们在模型识别返回的基础上,对市面上一些常见的保质期标签进行了收集,构建正则表达式,将物品生产日期和保质期从OCR识别结果中匹配出来,自动填写。
功能展示
| 功能名称 | 功能描述 |
|---|---|
| 登录 | 用户可以通过登陆界面登录小程序,来进行对物品的管理。 |
| AI识图 | 支持拍照进行AI识图,识别出物品的名称及种类。 |
| 搜索 | 用户可以通过小程序中的搜索功能进行对物品的搜索。 |
| 分类 | 用户可以对录入的物品进行分类,目前有食品,药品,护肤/化妆品三类。 |
| 过期提醒 | 用户可以设置物品的保质日期,小程序会在保质期到期时进行提醒。 |
| 多人数据共享 | 本小程序支持多人之间建立不同清单实现数据共享,方便多人管理共有数据。 |
| 保质期参考 | 在Q&A中进行常用物品保质期的展示 |
界面展示
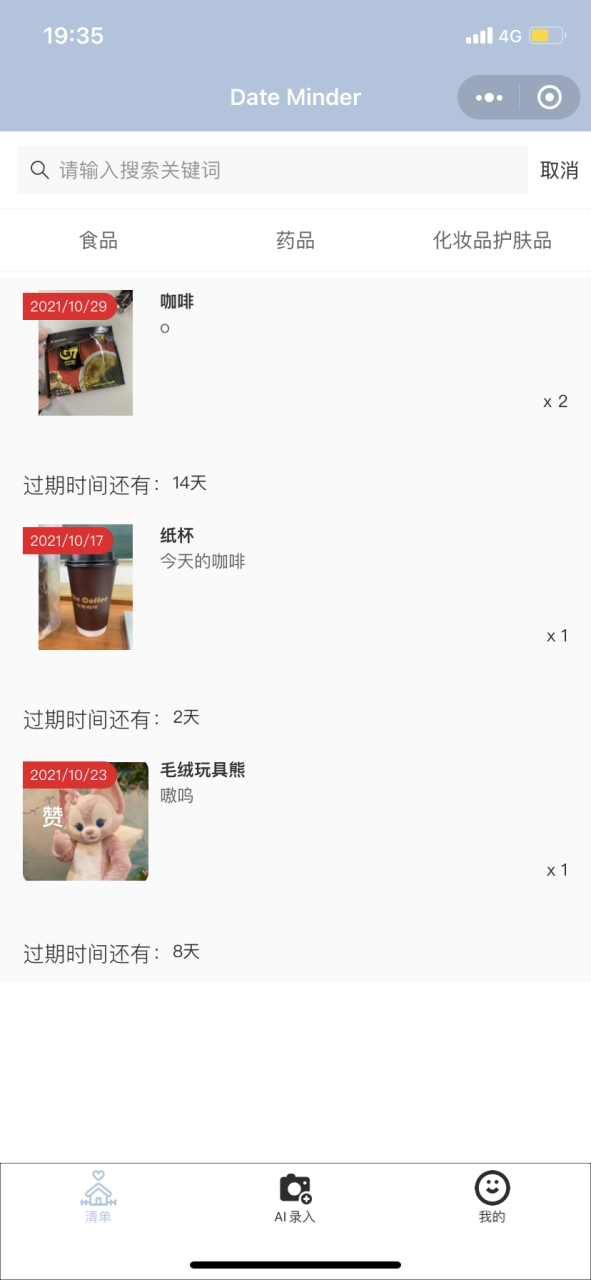
主页面
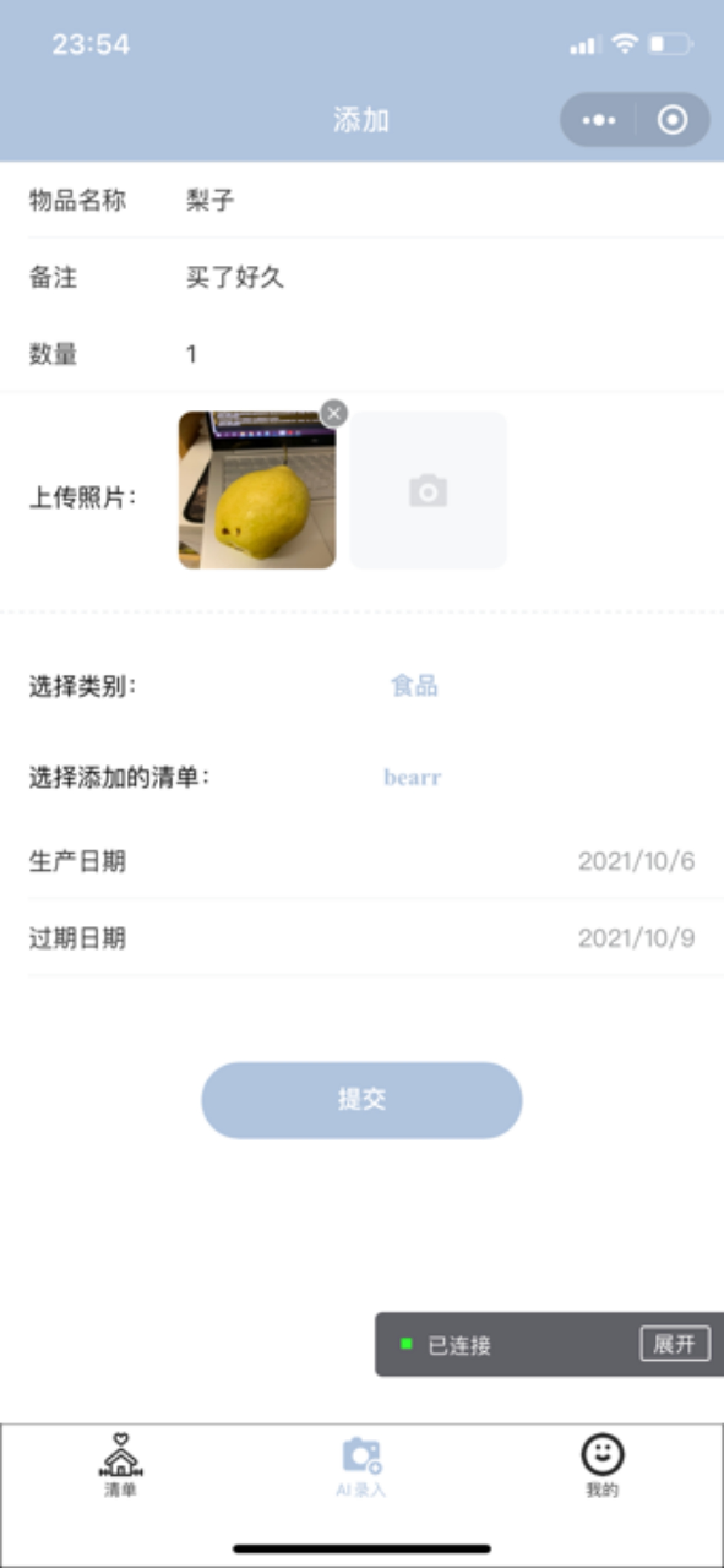
添加页面
共享清单
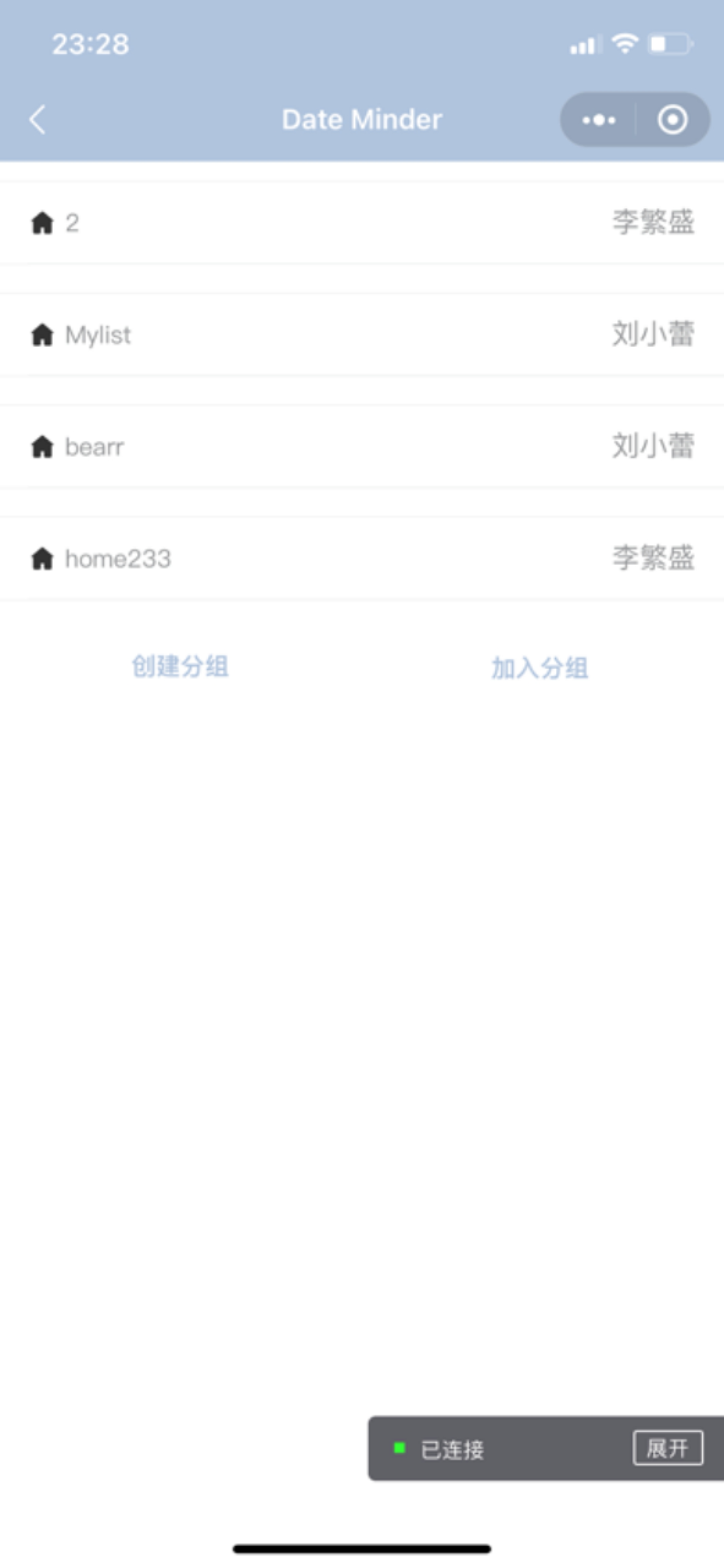
创建清单
我的界面
项目总结
加入语音输入功能可与现在市场上的智能音箱,百度旗下小度,小米旗下ai音箱等结合。还可与智能冰箱结合将Date Minder内物品信息显示在智能冰箱显示屏上。为用户生活带来更多便利。
坚持对软件的再开发与功能完善,未来会增设用户饮食规律提醒与建议与各类APP使用时长的健康提醒与报告,还将利用智能分析系统完善生成用户不常用物品清单功能。未来还将继续推出可以与智能家居链接的其他版本的软件。
从用户需求的角度,不断完善和开发新的功能,未来会不断地给用户带来新的体验和惊喜。未来的市场优势也一定属于我们。一款好的产品,不仅仅是一个工具,还将会提供一种美好的生活方式。绿色,节能,环保。