CLIP
总结
数据集:句子 - 图片对(将单词做成句子“A photo of a xxx”,对应图片)
优点:预训练、结构简单、在zero-shot(能够对从没见过的类别分类)上比有监督下ResNet50效果好、泛化性好。数据集大模型复杂,因此效果更好。
1、利用自然语言处理的监督信号做预训练:
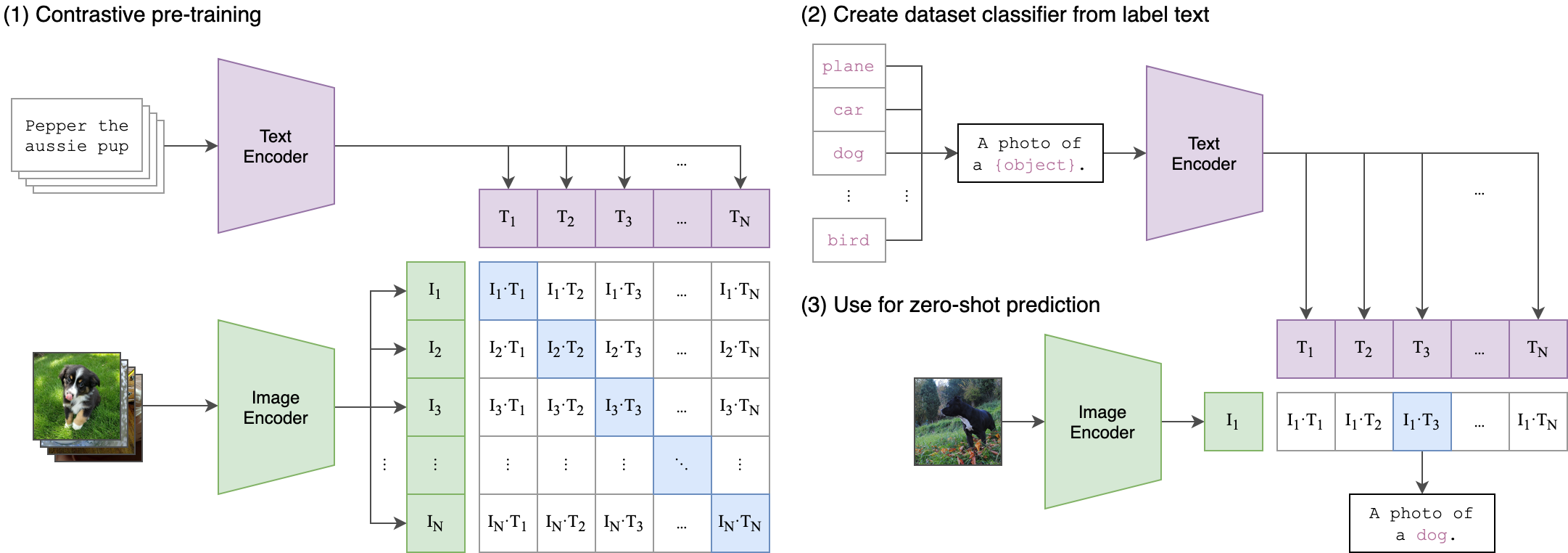
输入 图片和句子的配对
通过图片编码器,Resnet或vison transformer,得到图像特征
通过文本编码器,CBOW或Text Transformer,得到文本特征
然后通过投射层,合并图片和文本多模态的特征
计算cosine相似度得到logits
用logits和labels做交叉熵,计算出图片loss和文本loss,并求平均
然后对图片和文本进行对比学习,得到文本和图片的特征
正样本:配对的图片文本对,即左图中对角线上的样本,共n个
负样本:非对角线的元素,共$ n^2-n$ 个
数据集:OpenAI上4亿个文本和图片配对
2、用Prompt template做推理:
Prompt engineringh或Prompt ensemble
输入 图片
通过图片编码器得到特征,与每个文本特征求cos similarity
优点:得到语义特征,迁移性强(素描、动漫风格的物体都能识别出是什么)
可以应用在;目标检测(丰富检测出物体的信息)、用文本检索视频中物品出现的帧等
Abstract
现有模型都是通过提前定义好的标签集合(即物品类别)来预测,是有限制性的监督信号,无法识别新的类别;CLIP直接从自然语言处理中得到特征,即用爬取到的4亿图片-文本配对进行多模态的对比训练;在30个不同数据集上做预测效果都很好,比如在ImageNet上和有监督训练的ResNet-50打平手;预训练代码没开源,但模型在Github上开源了。
Bert、GPT、T5是在原始的文本数据上预训练一个模型,已经取得革命性成果,无论是自回归预测还是掩码完形填空的方式,都是自监督的方式,目标函数和下游任务无关,随着模型、数据、计算资源变多,性能也会变好,比如GPT-3无需特定领域的数据就能与之前精心设计的网络做对比。
对99年到21年工作的讨论,……,总之,有了Transformer后,出现了VirTex和ConVIRT这些和CLIP类似的工作,但这些模型由于数据和模型规模不够大,所以效果不够好;CLIP是ConVIRT的简化版,共尝试8个模型,包括Vision Transformer和ResNet,迁移学习效果和模型大小呈正相关。
Approach
1、监督的NLP
NLP中原来多是基于N-gram,无法用于跨模态zero-shot工作
2、造数据集
现有的数据量都不够大,自己收集了WebImage Text(WIT)作为数据集
3、训练方法
文本用Transformer即 CBOW 或 Text Transformer,图片用CNN即ResNet或Vision Transformer ;由于同一张图有不同的文字描述,不能用预测型任务,而是对比任务,即对比文本和图片是否配对。

I为图片的输入,n为batchsize,224 * 224 * 3
T为文本的输入,由于和图片配对,batchsize也是n,l为文本序列长度
通过编码器之后得到特征,使用投射层,学习一下如何从单模态到多模态,得到用来对比的特征I_e和T_e,最后用logits(求得的余弦相似度)和 ground truth(labels)求两个交叉熵损失函数,再将两个损失函 数求平均。
ground truth 是 arange 即从1到n,这样可以使对角线(即保证1-a 2-b……)上的元素为正样本;
Experiments
zore-shot Transfer推理
prompt:文本引导提示
由于文本的多义性且单个单词易产生歧义,将词语转化为句子“A photo of A xxx”计算出文本特征和图片特征对比,同时在句子中可以加入提示“A photo of A xxx,a type of xxx”,论文中用了80个提示模板,比如“A photo of a hard to see xxx”。